在开发 ItemVoid 时遇到了一个技术性问题,关于在大数据量下如何保证插入性能的情况下进行去重的问题。稍微在这里记录一下,也许以后还能再用到。
需要记录的内容如下:
| 字段名称 | 字段类型 | 描述 |
| discover_at | DATETIME NOT NULL | 物品发现时间 |
| material | VARCHAR(255) | 物品 Material 名称 |
| name | TEXT NOT NULL | 物品自定义名称 |
| lore | TEXT NOT NULL | 物品 Lores |
| nbt | LONGTEXT NOT NULL | 物品 NBT 信息 (可能很长) |
| bukkit_yaml | LONGTEXT NOT NULL | 用于通过 Bukkit API 重新取得相同物品的 YAML 序列化数据 |
需求分析为:
- 分批大量数据插入,预期为 150~1500 个物品/s,每 5 秒插入一次
- 由于应用侧缓存容量有限,因此数据库需要承担去重的任务,且需要保证去重的性能
分析去重字段
由于需要保存每个唯一物品到数据库中,因此排除使用 material, name 和 lore 三个字段,因为它们有很高的重复率(例如:相同 name 但不同 lore,名称和 lore 相同的不同问题),那么剩下的就只有 nbt 和 bukkit_yaml。而 bukkit_yaml 存储了一些额外信息(如:序列化时的服务器内部数据版本号等),并会导致在不同版本的 Minecraft 中创建多个重复物品。
最终选择 material + nbt 字段(nbt 字段不包含 material 信息,而一个物品需要这两个属性共同最终确定),它不但是 Minecraft 在存档文件中最终存储的格式,且除非物品真的有变动,否则在不同版本中 nbt 的序列化结果是一致的,减少了不必要的重复信息。
使用哈希
在 material + nbt 字段组合中,nbt 字段的数据类型是 LONGTEXT (因为它真的可以很长!),因此 nbt 字段无法被设置为唯一索引。在不使用索引的情况下,通过 SELECT 语句进行去重将导致严重性能问题(而 ItemVoid 又需要处理很大的数据量)。
一个解决方案是计算 material + nbt 字段组合的哈希值,将数据缩减至可被存入索引的长度。
根据项目属性的不同,ItemVoid 的物品数据并不是很重要,并可以重复从存档文件扫描导入。因此只需要计算一种哈希即可,对于我们的场景,SHA256 就足够了。
计算哈希值:
String sha256 = Hashing.sha256().hashString(material+" "+nbt, StandardCharsets.UTF_8).toString()设计表如下:
| 字段名称 | 字段类型 | 描述 |
| id | BIGINT NOT NULL PRIMARY KEY | 自增 ID |
| hash_sha256 | VARCHAR(255) NOT NULL | SHA256 哈希值 |
| discover_at | DATETIME NOT NULL | 物品发现时间 |
| material | VARCHAR(255) | 物品材料名称 |
| name | TEXT NOT NULL | 物品自定义名称 |
| lore | TEXT NOT NULL | 物品 Lores |
| nbt | LONGTEXT NOT NULL | 物品 NBT 信息 (可能很长) |
| bukkit_yaml | LONGTEXT NOT NULL | 用于通过 Bukkit API 重新取得相同物品的 YAML 序列化数据 |
在上线测试运行期间,很快就发现了新的问题:在使用 batch 批量插入时,即使插入失败,自增 ID 也会快速增长(InnoDB引擎),而去重又需要进行插入操作才能完成。因此很快自增 ID 以惊人的速度快速增长,但其中的空缺非常的大。在长时间的运行后,未来可能会耗尽自增 ID。
解决自增 ID 问题
一个简单的解决方案是将 SHA256 pad 到长整型,并直接用作主键 ID。这样不管插入多少次,有多少数据量,其范围总是控制在 BIGINT 范围内。
计算哈希值:
long sha256 = Hashing.sha256().hashString(material+" "+nbt, StandardCharsets.UTF_8).padToLong();关于非连续主键 ID 引发的树重平衡问题,索引的树重平衡会在后台自动进行,经过与团队商讨,表示 DB 的服务器性能令人安心,浪费一点性能问题不大。以及,尽管尝试插入的量很大,但绝大部分都是重复项,发现的新项相当少,不会有太多的机会破坏树平衡,因此可以接受。
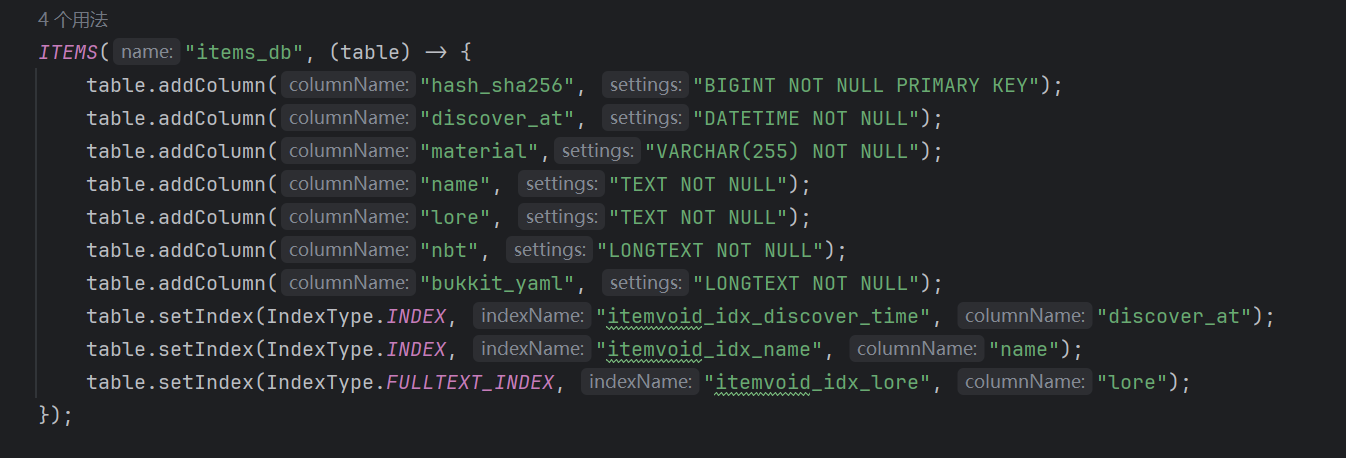
| 字段名称 | 字段类型 | 描述 |
| hash_sha256 | BIGINT NOT NULL PRIMARY KEY | SHA256 哈希值 |
| discover_at | DATETIME NOT NULL | 物品发现时间 |
| material | VARCHAR(255) | 物品材料名称 |
| name | TEXT NOT NULL | 物品自定义名称 |
| lore | TEXT NOT NULL | 物品 Lores |
| nbt | LONGTEXT NOT NULL | 物品 NBT 信息 (可能很长) |
| bukkit_yaml | LONGTEXT NOT NULL | 用于通过 Bukkit API 重新取得相同物品的 YAML 序列化数据 |
关于检索性能
检索通常基于 name 和 lore 字段进行检索。遗憾的是,由于团队使用此工具的场景通常是记不清具体物品的情况下使用,因此检索的关键词非常抽象,无法利用到索引优化。好在,使用的频率并不高,暂时不需要对检索性能进行过多优化。
对于 name 将使用全表扫描检索任意包含关键词,对于 lore 字段则可以可选的使用全文索引检索。